Core Computer Vision Services
alwaysAI provides a Python API, edgeIQ, that enables easy use of several core computer vision services, which include general computer vision models and popular functionality.
Image Classification
Image classification will take an image or part of an image and classify it into one of its categories. For example, a model trained on the Imagenet dataset would be able to correctly classify images in several different categories, including plants and animals. You should use a classifier if you have an image with a prominent object and want to know more about it. However, a classifier won’t locate an object in an image. For locating objects within an image, head to the Object Detection section.

Classification can be performed on an image using the
Classification class. The first step is to instantiate a
Classification object with the ID of the model to use. For
example:
classification = edgeiq.Classification("alwaysai/googlenet")
If the model is not a classification model, the instantiation will fail with
an error message indicating that the model can’t be used. Next, call the
object’s load() function to
initialize the inference engine and accelerator.
classification.load(engine=edgeiq.Engine.DNN)
Unless directly specified, the accelerator chosen will be the default for the
provided Engine. Now the image classifier is ready.
Use the classify_image()
function to classify an image. A confidence level can also be provided to
filter out results that don’t meet the required confidence level.
results = classification.classify_image(image, confidence_level=0.5)
The results object is of type ClassificationResults and contains
the duration of the inference, in seconds, and a list of predictions. Each
prediction is of type ClassificationPrediction and contains the
label and the confidence of that prediction.
Often, an image might contain several prominent objects. Since classification
only classifies the most prominent object in the image, it can be useful to
first perform
object detection
on the image, then cut out the important part of the image using the
cutout_image() function:
new_image = edgeiq.cutout_image(image, bounding_box_prediction)
The function takes as input an image and an
ObjectDetectionPrediction (the individual
result type of ObjectDetection) and returns a cutout of the input
image that is boxed in by the bounding box. For another example of this usage,
visit the
object detection section.
Classification Results
The Classification class provides the inference time and a list
of predictions in a ClassificationResults object. Each
prediction is of type ClassificationPrediction and contains
the label given by the model, and the confidence the model has in that label.
The confidence_level input to
classify_image() will
filter the results by confidence, and setting it to 0 will return a confidence
for each label. Since the confidence values are determined by the model, it
can be helpful to first return the full list before choosing a confidence
level threshold.
Object Detection
Object detection will take an image and identify and label specific objects within the image. For a complex image with multiple objects in view, object detection will provide a bounding box around each detected object, as well as a label identifying the class to which the object belongs.

Object detection can be performed on an image using the
ObjectDetection class. The first step is to instantiate an
ObjectDetection object with the ID of the model to use. For
example:
obj_detect = edgeiq.ObjectDetection("alwaysai/mobilenet_ssd")
If the model is not an object detection model, the instantiation will fail with
an error message indicating that the model can’t be used. Next, call the
object’s load()
function to initialize the inference engine and accelerator.
obj_detect.load(engine=edgeiq.Engine.DNN)
Unless directly specified, the accelerator chosen will be the default for the
provided Engine. Now the object detector is ready.
Use the detect_objects()
function to detect objects in an image:
results = obj_detect.detect_objects(image, confidence_level=.5)
The results object is of type ObjectDetectionResults and contains
the duration of the inference, in seconds, and a list of predictions. Each
prediction is of type ObjectDetectionPrediction and contains the
coordinates of a box around the object, the confidence, the label, and the
index of the label in the master label list of the model for
cross-referencing with that list.
It can be useful to visualize the detections. The image can be marked with
the results of the detection using the markup_image()
function:
new_image = edgeiq.markup_image(image, object_detection_predictions)
The markup_image() function takes as its input an
image (the one used for object detection) and a list of
ObjectDetectionPrediction objects and draws the bounding boxes and
labels on the image.
Object Detection Results
The ObjectDetection class provides the inference time and a list
of predictions in an ObjectDetectionResults object. Each
prediction is of type ObjectDetectionPrediction and contains
the label given by the model, the confidence the model has in that label,
a BoundingBox around the detected object, and the index of the
label in the model’s master list. The confidence_level input to
detect_objects() will
filter the results by confidence, and setting it to 0 will return all
detections for the image.
Once you have a list of ObjectDetectionPrediction objects, you
may want to perform processing for only a few specific objects. For example,
you may want to perform processing on all potted plants and chairs in the
image. To do that, call
filter_predictions_by_label:
filtered_predictions = edgeiq.filter_predictions_by_label(predictions, ['pottedplant', 'chair'])
Another tool enables filtering predictions by bounding box area. This could be used, for example, to filter out objects that are far in the distance:
filtered_predictions = edgeiq.filter_predictions_by_area(predictions, 1000)
The ObjectDetectionPrediction objects can be used to perform more
specific classification on detected objects. For example, you may want to
detect all birds flying by a window, then use a classifier to determine the
type of each bird. Start by filtering out all detected birds:
filtered_predictions = edgeiq.filter_predictions_by_label(predictions, ['bird'])
Then, for each detected bird slice out that portion of the image and pass it to a classifier:
for prediction in filtered_predictions:
bird_image = edgeiq.cutout_image(image, prediction.box)
bird_type = classification.classify_image(bird_image)
ObjectDetectionPrediction objects, or really any predictions with a
box (of type BoundingBox) and confidence, can be used in
conjunction with object tracking. The CorrelationTracker class takes
in a prediction with a bounding box and updates the location of the bounding
box as new frames are provided. For each frame, the tracker returns all the
predictions with updated bounding box location and confidence. The
CentroidTracker class takes in a list of predictions and associates
each with an object ID. For each frame, the tracker will provide a dictionary
mapping the object ID to each provided prediction.
Bounding Boxes
The BoundingBox class represents a box that bounds a region of
interest in an image. It is defined by two points, (start_x, start_y) and
(end_x, end_y).
box = edgeiq.BoundingBox(start_x=100, start_y=100, end_x=200, end_y=200)
Two bounding boxes can be compared to see if they represent the same box, and
a bounding box can be multiplied by a scalar to perform scaling along with
scaling an image. Attributes include width, height, area, and
center. center returns a tuple representing the center point.
An important aspect of bounding boxes is their relationship
with other boxes or regions of interest in the image. The
compute_distance() function
can be used to compute the distance between the centers of two bounding
boxes. The get_intersection()
function returns a new BoundingBox object representing the
intersection between the current bounding box and another, and the
compute_overlap() function
returns the fraction of the current bounding box that is overlapped by another.
The compute_distance() and
compute_overlap() functions could
be used together, for example, to determine if a person is riding a bicycle
or walking. If a person is riding a bicycle, the distance
between the person and bicycle should remain fairly consistent over multiple
frames, and the person’s bounding box should be significantly overlapped by
the bicycle’s bounding box.
Semantic Segmentation
Semantic segmentation is essentially image classification at a pixel level, as it takes an image and assigns a class to each pixel in the image. This can be helpful whenever you need more precision than is provided by object detection, since semantic segmentation gives you a more complete picture of the exact boundaries of the different elements in the image. Semantic segmentation can be used for tasks such as medical imaging analysis, surface area calculations, precision agriculture, and detection of surface defects during manufacturing.

Semantic segmentation can be performed on an image using the
SemanticSegmentation class. The first step is to instantiate a
SemanticSegmentation object with the ID of the model to use. For
example:
semantic_segmentation = edgeiq.SemanticSegmentation("alwaysai/enet")
(If the model is not a semantic segmentation model, the instantiation will fail with an error message indicating that the model can’t be used.)
Next, call the object’s load()
function to initialize the inference engine and accelerator:
semantic_segmentation.load(engine=edgeiq.Engine.DNN)
Unless directly specified, the accelerator chosen will be the default for the
provided Engine. Now the semantic segmentation
object is ready. Use the
segment_image()
function to detect objects in an image:
results = semantic_segmentation.segment_image(image)
The results object is of type SemanticSegmentationResults and
contains the duration of the inference (in seconds), and a class map, which maps
a class to each pixel.
Since it can be useful to visualize the segmentation, you can create a color mask by using
build_image_mask() and
then apply the mask to the image using
blend_images():
color_mask = semantic_segmentation.build_image_mask(results.class_map)
blended_image = edgeiq.blend_images(image, color_mask, alpha=0.5)
The blend_images() function takes as its input an
image (the same image that you used in the segment_image() function), the color map generated
by build_image_mask(),
and the alpha factor, which determines the opacity of the color mask and
image. By setting alpha to 0.5, both the mask and the image will have equal
opacity.
Instance Segmentation
Instance segmentation combines object detection and semantic segmentation together. In object detection, individual objects are classified and localized and in semantic segmentation, each pixel in a region is classified. Instance segmentation detects instances of an object, similar to object detection and classifies each pixel within the detected region. In addition to identifying and localizing objects in an image, instance segmentation provides additional information about the pixels covered by the object. This enables instance segmentation to be used in applications requiring a detailed understanding of the scene such as self-driving cars, medical scans and satellite imagery.
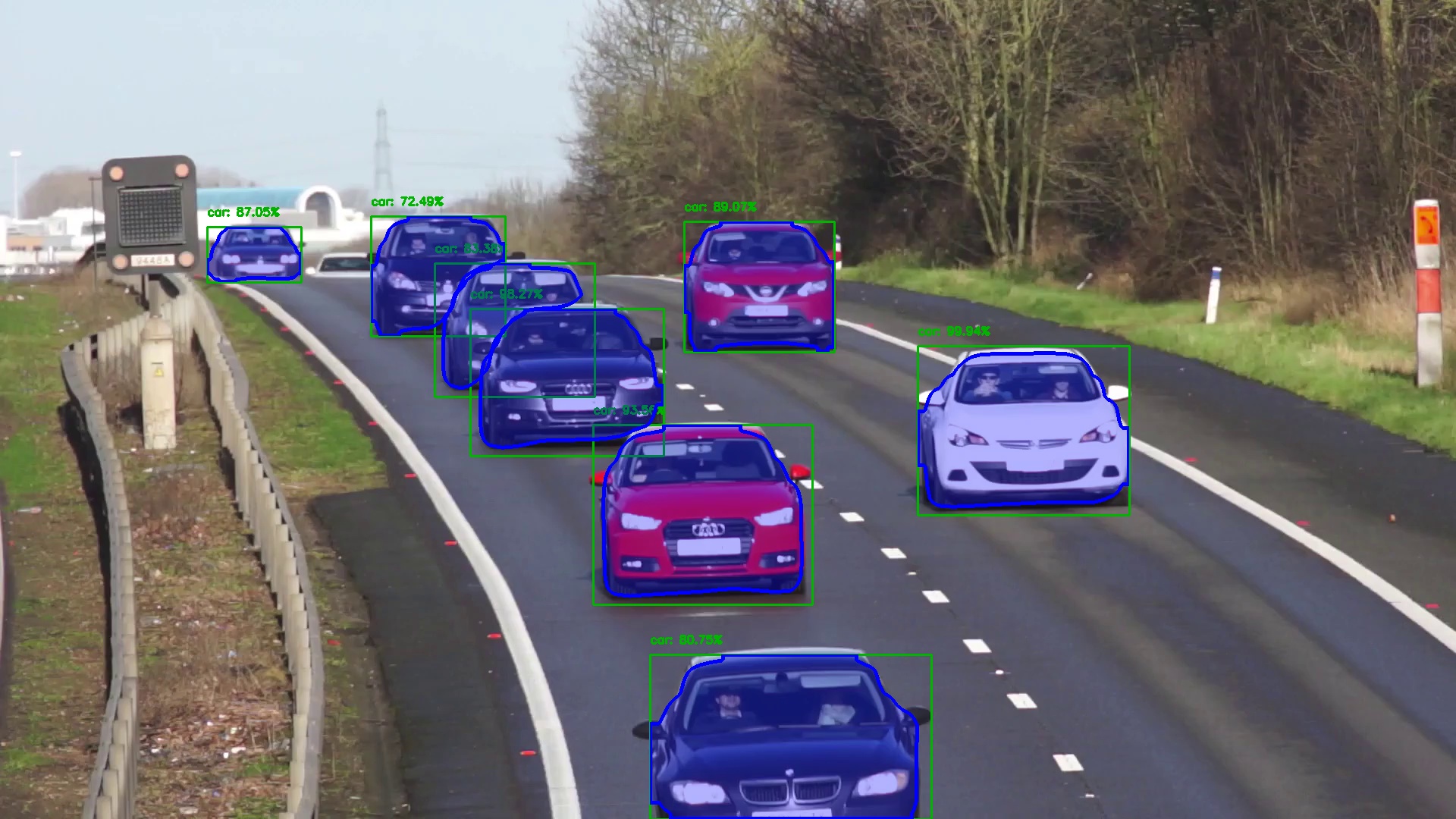
Instance segmentation can be performed on an image using the
InstanceSegmentation class. The first step is to instantiate a
InstanceSegmentation object with the ID of the model to use. For
example:
instance_segmentation = edgeiq.InstanceSegmentation("alwaysai/mask_rcnn")
(If the model is not an instance segmentation model, the instantiation will fail with an error message indicating that the model can’t be used.)
Next, call the object’s load()
function to initialize the inference engine and accelerator:
instance_segmentation.load(engine=edgeiq.Engine.DNN)
Unless directly specified, the accelerator chosen will be the default for the
provided Engine. Now the instance segmentation
object is ready. Use the
segment_image()
function to detect objects and its corresponding pixels in an image:
results = instance_segmentation.segment_image(image)
The results object is of type InstanceSegmentationResults and
contains the duration of the inference, in seconds, and a list of predictions. Each prediction is of type InstanceSegmentationPrediction and contains the coordinates of a box around the object, contours and hierarchy for its corresponding mask, the label, and the index of the label in the master label list of the model for cross-referencing with that list.
It can be useful to visualize the detections. The image can be marked with the results of the detection using the markup_image() function:
new_image = instace_segmentation.markup_image(image, instance_segmenation_predictions)
The markup_image() function takes as its input an image (the one used for instance segmentation) and a list of
InstanceSegmentationPrediction objects and draws the bounding boxes, masks and
labels on the image.
Pose Estimation
The Pose Estimation service takes an image of a human and assigns 18 key points to features in that image which correspond to specific body parts, and which allow one to determine how these parts are positioned. Pose Estimation has many use cases, including activity recognition and augmented reality.

Pose Estimation can be performed on an image using the PoseEstimation
class. The first step is to instantiate a PoseEstimation object with
the ID of the model to use. For example:
pose_estimator = edgeiq.PoseEstimation("alwaysai/human-pose")
Next, call the object’s load()
function to initialize the inference engine and accelerator.
pose_estimator.load(engine=edgeiq.Engine.DNN)
Unless directly specified, the accelerator chosen will be the default for the
provided Engine. Now the pose estimator is ready.
The returned results object is of type HumanPoseResult and contains an
array of the key points indicating body parts, where the order of the parts in the array
is as follows:
Body Part |
Output |
|---|---|
Nose |
0 |
Neck |
1 |
Right Shoulder |
2 |
Right Elbow |
3 |
Right Wrist |
4 |
Left Shoulder |
5 |
Left Elbow |
6 |
Left Wrist |
7 |
Right Hip |
8 |
Right Knee |
9 |
Right Ankle |
10 |
Left Hip |
11 |
Left Knee |
12 |
Left Ankle |
13 |
Right Eye |
14 |
Left Eye |
15 |
Right Ear |
16 |
Left Ear |
17 |
Object Tracking
Object tracking can be used to determine whether a bounding box from a new
detection is delineating the same object as a previous detection. This
enables you to track a unique object across a series of frames. edgeIQ
has two trackers: the CentroidTracker
and the CorrelationTracker.
Centroid Tracker
The CentroidTracker matches a new set of bounding boxes with a
previous set of bounding boxes by finding the optimal matching that minimizes
the distance of all pairs. To use the CentroidTracker in your app,
first instantiate an ObjectDetection object and load the engine and
accelerator using the load()
function. The object detector will be used to create bounding boxes around
the objects we’ll be tracking:
obj_detect = edgeiq.ObjectDetection("alwaysai/mobilenet_ssd")
obj_detect.load(engine=edgeiq.Engine.DNN)
Then instantiate the CentroidTracker object:
tracker = edgeiq.CentroidTracker()
Perform an object detection using the
detect_objects() function,
which will return a ObjectDetectionResults object containing a
list of ObjectDetectionPrediction:
results = obj_detect.detect_objects(frame)
Update the tracker by calling the
update() function.:
objects = tracker.update(results.predictions)
The update() function returns a
dictionary with a unique key for each object, as well as the
ObjectDetectionPrediction that goes with that object. After each
detection, the dictionary will match the new bounding boxes to the original
object IDs, giving you the ability to perform processing for a specific
object across multiple detections.
The deregister_frames and max_distance parameters can be used to
fine-tune your tracking. deregister_frames instructs the tracker how long
it should keep tracking an object after it’s detection has been lost. You’ll
see that the bounding box of a tracked object will stay in the same location
for deregister_frames frames after it is lost, finally disappearing. The
max_distance parameter determines the longest allowable distance for a
match. If the same object has moved more than max_distance between
detections, it will be treated as a new object.
A common task is to use the output of a tracker to generate a new predictions
list to use markup_image(). Here’s an example from
the detector_tracker starter app:
tracked_predictions = []
for (object_id, prediction) in objects.items():
# Use the original class label instead of the prediction
# label to avoid iteratively adding the ID to the label
class_label = obj_detect.labels[prediction.index]
prediction.label = "{}: {}".format(object_id, class_label)
tracked_predictions.append(prediction)
frame = edgeiq.markup_image(
frame, tracked_predictions, show_labels=True,
show_confidences=False, colors=obj_detect.colors)
Kalman Tracker
The KalmanTracker can be used to improve the accuracy of tracking
for objects that move in predictable ways. The KalmanTracker uses a
Kalman Filter for each tracked object and uses the history of detected locations
to estimate the future location. It works especially well in scenarios such
as cars driving by and people walking on a sidewalk, where the
CentroidTracker may fail to match objects if a fast-moving object has
moved outside the max_distance range.
The interface and usage of KalmanTracker is identical to
CentroidTracker.
Correlation Tracker
The CorrelationTracker can be used to add precision to your
tracking. This can be useful for scenarios where detections may be
intermittent or spaced out in time. The CorrelationTracker uses the
same distance minimization algorithm to match bounding boxes, but uses a
correlation tracking algorithm to determine the new position of a bounding
box when the detection is lost.
The interface of CorrelationTracker is identical to
CentroidTracker except for the additional max_objects
parameter. The correlation tracking algorithm is CPU intensive, and can
quickly overwhelm an SBC with limited resources when too many devices are
tracked simultaneously. Setting max_objects will limit the number of
devices that will use the correlation tracking algorithm and keep your app
from overloading the system.
Zones
Regions of interest, or zones, help tie results inferred with computer vision models
to physical spaces. You can use zones with ObjectDetectionResults and results
returned from a tracking update() function to
draw additional conclusions about the real-world environment in which the application is running.
Capturing an Image
Since zones map a three-dimensional space to a list of points that you can use in your application, to use zones appropriately you should use a static viewpoint. Once you have a stationary camera installed, you can use our data collection application to capture a representative image.
Uploading an Image
Once you have your new image, you need to upload it to your Datasets. You will want to keep the images you use for zones separate from those you use for annotation. If you don’t have a Dataset to use for zones, you can create a new one.
From your Datasets page, click the Upload button. From there, you can choose a Dataset you have created for drawing zones, or you can choose to create a new one.
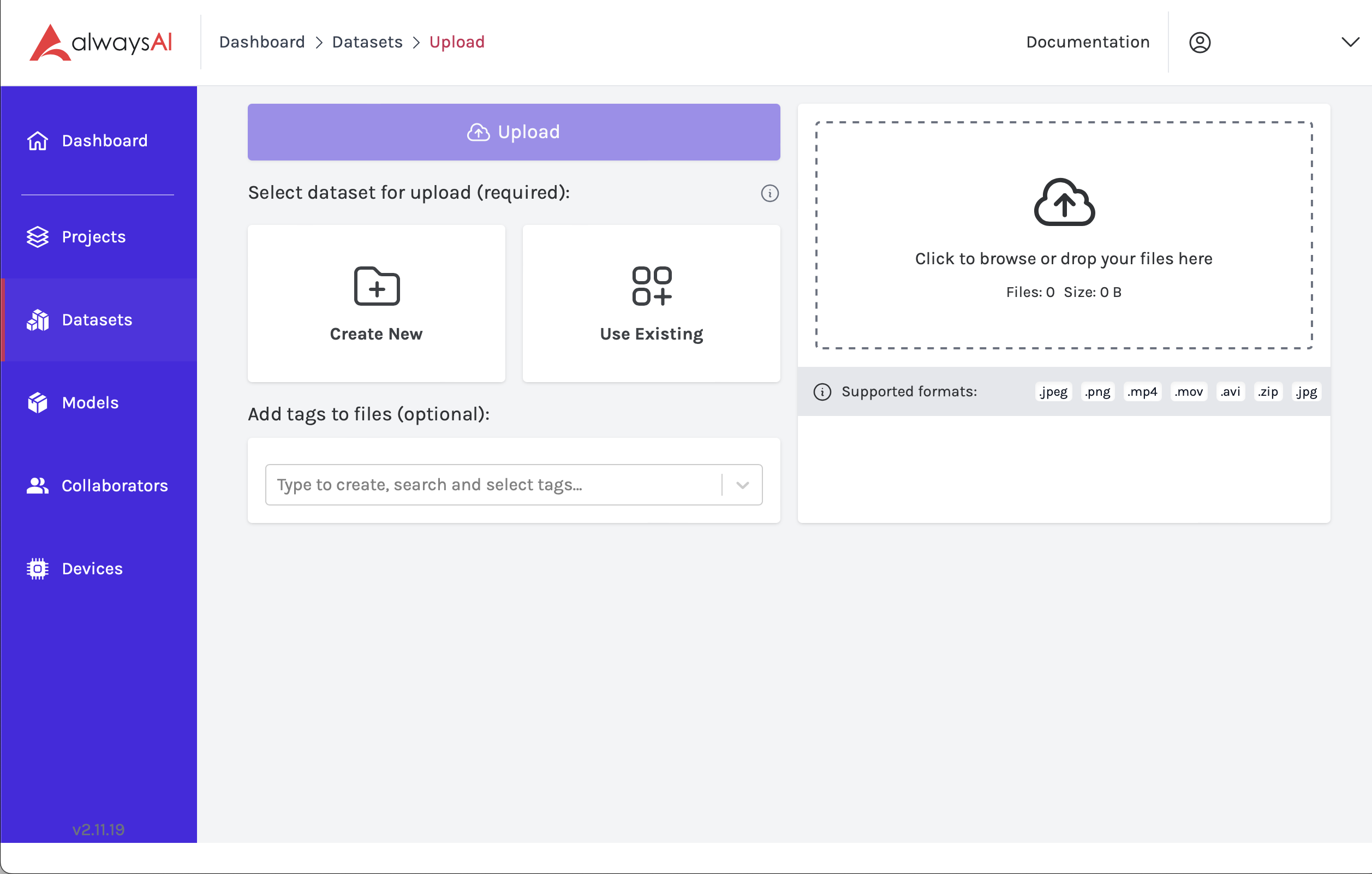
Once you have created a Dataset and have uploaded your image, navigate back to the Datasets tab and click on the Dataset that includes your new image.
From there you can select the image you would like to draw zones for, and follow the tutorial listed in the section below.
Creating Zones
Our zone tutorial walks through how to create, modify, and export zones. When you have generated your zones, and exported the configuration file, place the zone_config.json file in your application directory. You can put this file anywhere in the application directory, however you will need to note the relative path to your main application file in order to load the zone configuration file, which is described in the next section.
Using Zones in an Application
Once you have created your zone file as described above, you can integrate them into
your application using the edgeIQ API. Here is an example of how to
filter ObjectDetectionResults by zones, and subsequently publish the results
to the analytics cloud API. It also demonstrates how to mark up an image with zones:
my_zones = edgeiq.ZoneList.from_config_file("zone_config.json")
<get image>
results = obj_detect.detect_objects(image, confidence_level=.5)
image = edgeiq.markup_image(
image, results.predictions, colors=obj_detect.colors)
zone_detect_results = my_zones.get_predictions_in_zone(results, zone_name)
obj_detect.publish_analytics(zone_detect_results)
image = my_zones.markup_image_with_zones(
image,
fill_zones=True,
color=(255, 0, 0))
Related Tutorials